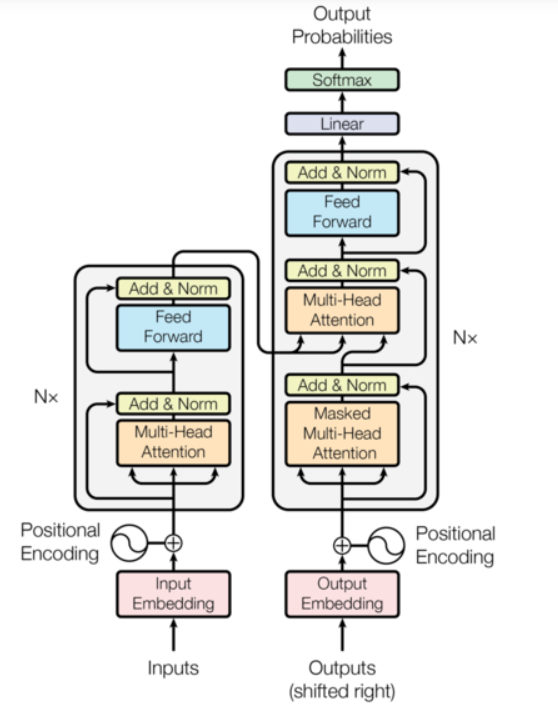
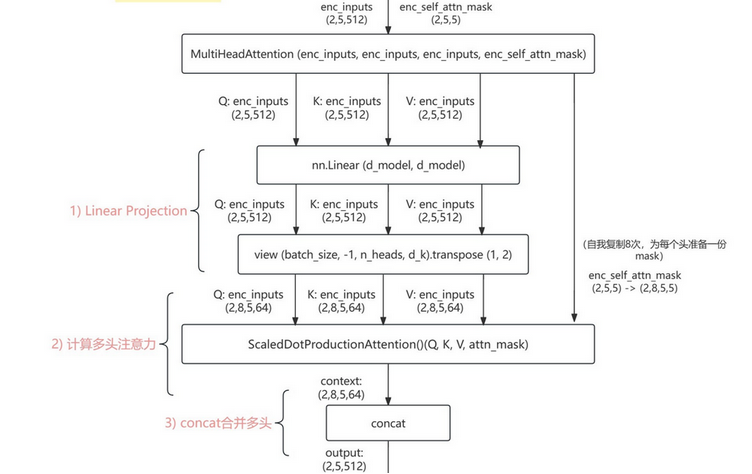
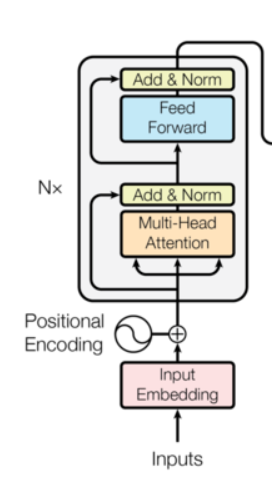
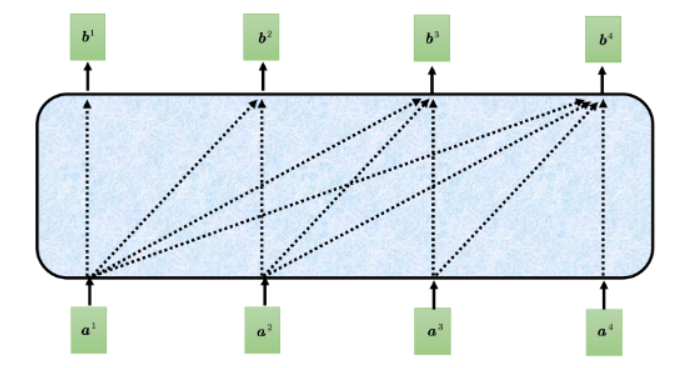
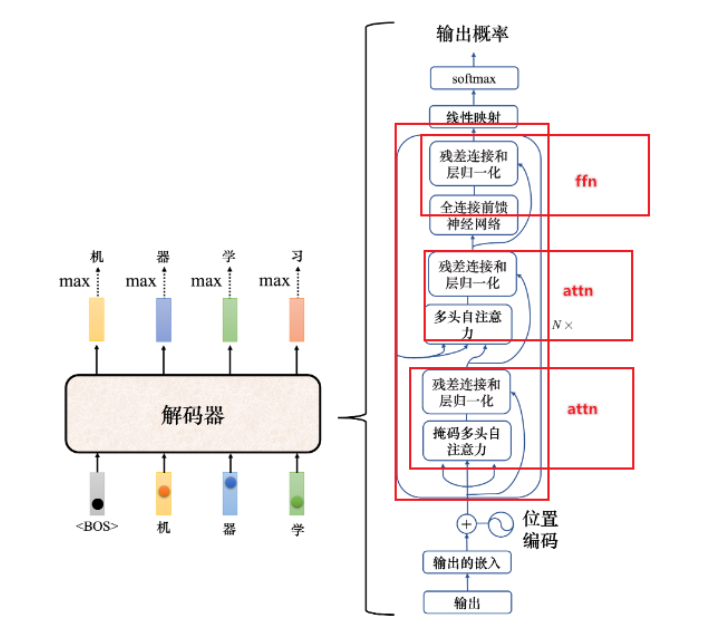
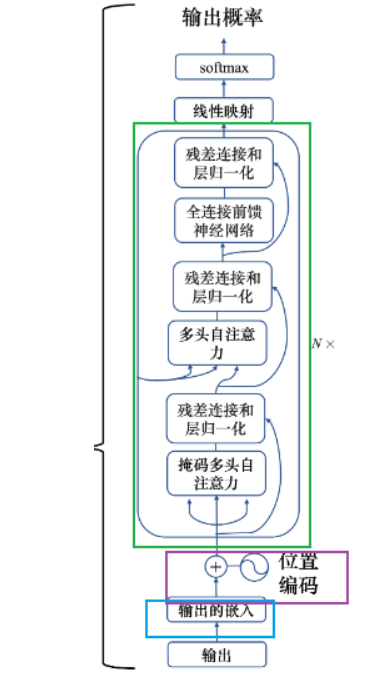
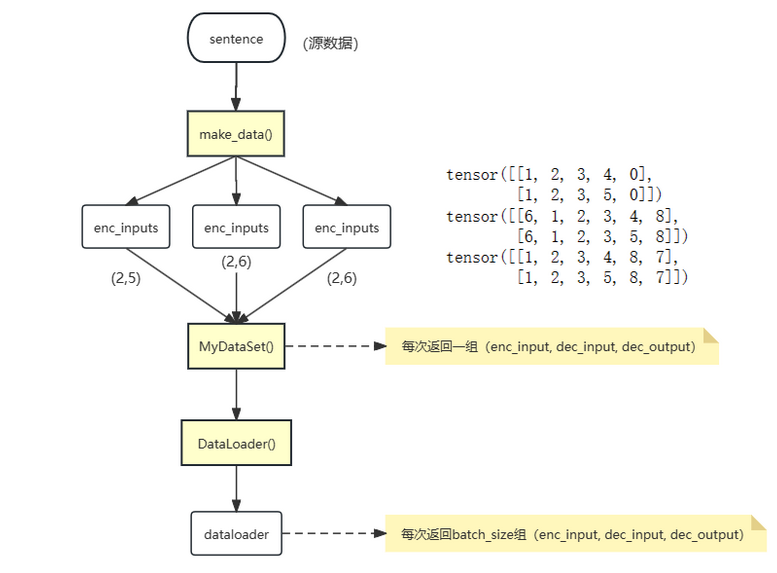
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| ====================================================================================================
Layer (type:depth-idx) Output Shape Param
====================================================================================================
Transformer [12, 9] --
├─Encoder: 1-1 [2, 5, 512] --
│ └─Embedding: 2-1 [2, 5, 512] 3,072
│ └─PositionalEncoding: 2-2 [2, 5, 512] --
│ │ └─Dropout: 3-1 [2, 5, 512] --
│ └─ModuleList: 2-3 -- --
│ │ └─EncoderLayer: 3-2 [2, 5, 512] 3,150,336
│ │ └─EncoderLayer: 3-3 [2, 5, 512] 3,150,336
│ │ └─EncoderLayer: 3-4 [2, 5, 512] 3,150,336
│ │ └─EncoderLayer: 3-5 [2, 5, 512] 3,150,336
│ │ └─EncoderLayer: 3-6 [2, 5, 512] 3,150,336
│ │ └─EncoderLayer: 3-7 [2, 5, 512] 3,150,336
├─Decoder: 1-2 [2, 6, 512] --
│ └─Embedding: 2-4 [2, 6, 512] 4,608
│ └─PositionalEncoding: 2-5 [2, 6, 512] --
│ │ └─Dropout: 3-8 [2, 6, 512] --
│ └─ModuleList: 2-6 -- --
│ │ └─DecoderLayer: 3-9 [2, 6, 512] 4,200,960
│ │ └─DecoderLayer: 3-10 [2, 6, 512] 4,200,960
│ │ └─DecoderLayer: 3-11 [2, 6, 512] 4,200,960
│ │ └─DecoderLayer: 3-12 [2, 6, 512] 4,200,960
│ │ └─DecoderLayer: 3-13 [2, 6, 512] 4,200,960
│ │ └─DecoderLayer: 3-14 [2, 6, 512] 4,200,960
├─Linear: 1-3 [2, 6, 9] 4,617
====================================================================================================
Total params: 44,120,073
Trainable params: 44,120,073
Non-trainable params: 0
Total mult-adds (M): 88.24
====================================================================================================
Input size (MB): 0.00
Forward/backward pass size (MB): 6.04
Params size (MB): 176.48
Estimated Total Size (MB): 182.52
====================================================================================================
|