梯度消失和梯度爆炸
1、什么是梯度消失和梯度爆炸?
- 梯度消失:在每次更新时,参数更新过小几乎不会移动,导致模型无法学习。
- 梯度爆炸:参数更新过大,破坏了模型的稳定收敛。
2、为什么会出现梯度消失和梯度爆炸?
根本原因是深层次的神经网络模型的权重在反向传播过程中梯度的传播特性。层层网络下,参数矩阵在反向传播中反复累积的相乘,容易受到数值下溢问题的影响,当将太多的概率乘在一起时,它们的乘积可能非常大,也可能非常小。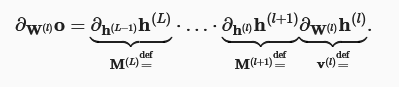
- 不合适的初始化参数会导致梯度的消失和爆炸。
- 长期依赖问题,RNN中序列过长,梯度可能会逐渐衰减,远距离依赖的信息无法传播从而导致梯度消失。
- 激活函数选择不合适,例如sigmoid是以前网络中导致梯度消失的一个常见原因。
- 网络复杂度过高,参数量过大,可能会导致梯度值非常大,需要特殊的技巧来处理深层多参数模型。
3、如何缓解梯度消失或梯度爆炸问题?
针对梯度消失:
- 使用合适的参数初始化方法,如Xavier或者He初始化方法。
- 使用合适的激活函数,如目前常用的ReLU系列等。
- 使用批量归一化。
针对梯度爆炸:
- 梯度裁剪,限制梯度的大小。
- 加入权重正则化,在损失函数中加入L1/L2正则项,限制权重大小
- 合适的参数初始化方法,同上面。
- 使用更小的学习率。
4、题外:正则化
正则化是为了防止模型过拟合,提高其泛化能力的方法。
有以下一些正则化方法:
- 在损失函数中加入权重的L2正则惩罚项。
- 数据增强。
- Dropout。
- 批量归一化。
- 权重衰减。
- 早停技术。